分布式自增ID生成方案
推荐美团的leaf方案
1.UUID
一点代码即可实现
优点
- 简单,代码方便
- 性能好,
- 全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
- 无序
- UUID字符串存储,查询效率低
- 存储空间大
- 传输数据量大
- 字符串无任何意义
2.数据库自增ID策略
弄一个mysql,这个MYSQL只干一件事生成ID给分布式机器用
优点:
- 非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
- ID号单调自增,可以实现一些对ID有特殊要求的业务。
缺点:
-
强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
-
ID发号性能瓶颈限制在单台MySQL的读写性能。
用多台MYSQL设置步长和机器数相等,比如三台机器,第一台生成ID为1,4,7 第二台为2,5,8 第三台为3,6,9但是分布式系统本身性能极高,流量极大,MYSQL的抗并发几下就挂了,而且随着订单量增加水平扩展太难了
3.snowflake
优点
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID(64位)。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。
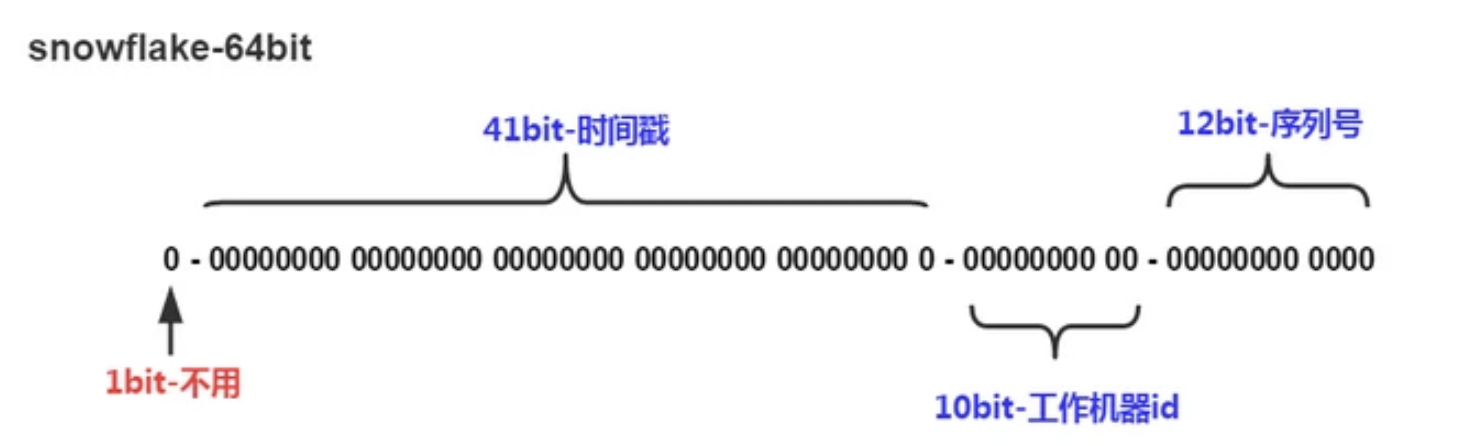
优点:
1.毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
2.不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
3.可以根据自身业务特性分配bit位,非常灵活。
缺点:
强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
3.Redis生成ID
因为Redis是单线程的,也可以用来生成全局唯一ID。可以用Redis的原子操作INCR和INCRBY来实现。
此外,可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis,可以初始化每台Redis的值分别是1,2,3,4,5,步长都是5,各Redis生成的ID如下:
A:1,6,11,16
B:2,7,12,17
C:3,8,13,18
D:4,9,14,19
E:5,10,15,20
这种方式是负载到哪台机器提前定好,未来很难做修改。3~5台服务器基本能够满足需求,都可以获得不同的ID,但步长和初始值一定需要事先确定,使用Redis集群也可以解决单点故障问题。
另外,比较适合使用Redis来生成每天从0开始的流水号,如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量较大。
3)集群的时候需要提前定好负载分布,扩充以后很难修改。
4.美团leaf
4.1 Leaf-segment号段模式 加强了数据库模式,采取一次取出来1000个ID,减少了对数据库的请求
优点:
- Leaf服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景。
- 容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服务。
缺点:
- ID号码不够随机,能够泄露发号数量的信息,不太安全。
- DB宕机会造成整个系统不可用(用到数据库的都有可能)。
4.2 leaf-snowflake
算法和Twitter的基本一致,但是用zookeeper解决了时钟回拨的问题
各种方案
https://blog.csdn.net/weixin_40757930/article/details/123925231
https://blog.csdn.net/minkeyto/article/details/104943883
美团leaf
水平很高,讲解了为什么,解决了什么问题,可见作者底层功力深厚
https://tech.meituan.com/2017/04/21/mt-leaf.html
https://github.com/Meituan-Dianping/Leaf/blob/master/README_CN.md
学了一招 mvn spring-boot:run 能命令行直接启动服务
9种方案https://mp.weixin.qq.com/s?__biz=MzAxNTM4NzAyNg==&mid=2247483785&idx=1&sn=8b828a8ae1701b810fe3969be536cb14&chksm=9b859174acf21862f0b95e0502a1a441c496a5488f5466b2e147d7bb9de072bde37c4db25d7a&token=745402269&lang=zh_CN#rd
无特殊说明,文章均为月小升原创,欢迎转载,转载请注明本文地址,谢谢